![[CAIDA - Center for Applied Internet Data Analysis logo]](/images/caida_globe_faded.png "Go to CAIDA home page")
| Research Sponsored by: | |||
|---|---|---|---|
 |  |
Principal Investigators
Dr. Kimberly C. Claffy, CAIDA, University of California - San Diego
Dr. Constantinos Dovrolis, University of Delaware
Project Summary
The ability for an application to adapt its behavior to changing network conditions depends on the underlying bandwidth estimation mechanism that the application or transport protocol uses. As such, accurate bandwidth estimation algorithms and tools can benefit a large class of data-intensive and distributed scientific applications. However, existing tools and methodologies for measuring network bandwidth metrics, (such as capacity, available bandwidth, and throughput) are mostly ineffective across real Internet infrastructures.
We propose to improve existing techniques and tools, and to test and integrate them into DOE and other network infrastructures. The proposed effort will overcome limitations of existing algorithms whose estimates degrade as the distance from the probing host increases. The experience of the investigators with both VPS (Variable Packet Size) and PTD (Packet Train Dispersion) probing techniques makes us uniquely qualified to take on this research challenge. As we improve the algorithms for both techniques, we will incorporate our knowledge into an integrated tool suite that offers insights into both hop-by-hop and end-to-end network characteristics. We also will investigate mechanisms for incorporating bandwidth measurement methodologies into applications or operating systems, so that the applications quickly reach the highest throughput a path can provide. Finally, we will examine ways in which routing protocols, traffic engineering, and network resource management systems can use accurate bandwidth estimation techniques in order to improve overall network efficiency.
Contents
1 Background and Significance2 Definitions and Classifications
3 Previous Results
4 Research Objectives and Methods
4.1 Research on Bandwidth Measurement Methodologies
4.2 Research on Bandwidth-Aware Protocols
5 Infrastructures for testing
6 Task list
7 Conclusion
1 Background and Significance
Scientific experiments in the fields of high energy nuclear/particle physics, astronomy, or biotechnology, can generate terabytes of data; experiments planned for the near future are expected to produce petabytes. Such large data sets will be made available to thousands of scientists around the world via a high performance computing and communication infrastructure. Scientists must be able to analyze results of these experiments as if these petaBytes were stored in their desktop hard drive, to collaborate in `labs without walls', and to access remote instruments as if these instruments were located next door. Research projects such as the Grid Physics Network (GriPhyN) and the Particle Physics Data Grid (PPDG) are motivated by the computing and networking needs of this new generation of scientific experiments.
Transfer of petabytes in a timely fashion creates unique challenges for the underlying communication networks. Expensive links and switches graded as `terabyte-capable' do not guarantee that applications will be able to use all this potential bandwidth. It has been demonstrated that, especially in high latency and high bandwidth paths, data intensive applications often achieve throughput of no more than tens of Mbps, regardless of network capacity graded orders of magnitude higher. For instance, see Dunigan's work on ESnet [1], Cottrell's experiments over the NTON [2], or Mathis' recent presentation at Extreme Networking (https://www.caida.org/publications/presentations/extreme0001/). Several factors contribute to mismatches between the capacity of underlying network technology and application throughput. The latter depends on the transport protocol design (flow and congestion control algorithms), transport protocol implementation and selection of its tunable parameters, intensity and behavior of network cross traffic, throughput of network interfaces and operating system at end-hosts, and the capacities and MTUs (Maximum Transmission Units) of underlying link technologies. All of these components require careful examination and likely design refinements if we are to build applications that can really use the terabit capacities promised by optical switching and DWDM technologies.
Capacity, bandwidth, and throughput all quantify aspects of data transfer rate across a network, which is the main performance consideration for data intensive scientific applications. A major component missing from today's applications and transport protocols is the ability to measure and predict the throughput achievable across a network path. Instead, transport protocols, mainly TCP, attempt to dynamically and adaptively search for the maximum possible rate using techniques such as slow start or congestion avoidance, which often lead to network underutilization and low application throughput. We could avoid these problems if we had measurement methodologies that could accurately monitor the maximum possible bandwidth (i.e., capacity) in a network path, as well as the maximum allowable bandwidth (i.e., available bandwidth). With accurate bandwidth-related information, the transport protocol and applications could achieve higher throughput and react faster to changing network conditions. Accurate bandwidth assessment techniques would also allow a quantum jump in the functionality of Internet traffic engineering, e.g., agents in routers or proxies that could inform routing protocols of overloaded paths, and/or provide guidance to service differentiation mechanisms (e.g., scheduling, input traffic limiting) for overloaded classes of traffic.
At the highest level, our objectives are twofold:
- Design, implement, and experiment with bandwidth measurement methodologies that assess capacity and available bandwidth along a network path accurately, dynamically (i.e., in real-time), and efficiently (i.e., without significant measurement traffic overhead). Particular emphasis to testing methodologies on real commodity Internet paths will maximize the applicability of this effort.
- Design, implement, and experiment with mechanisms that can feed these bandwidth measurements back to transport protocols and applications on end hosts, and to routing and QoS middleware in the network, in order to increase network utilization and end-to-end performance.
We refer to the first part of the work as Bandwidth Measurement Methodologies (BMMs), and to the second part as Bandwidth-Aware Protocols (BAPs). In Section 4, we will expand more on these two objectives, as well as other benefits from this work.
Numerous network measurement projects in the last decade, mostly focusing on performance evaluation, have defined two generations of network performance measurement activities. We now envision a third generation. Each generation builds on the measurement tools and experiences of the previous ones.
- First generation: In the eighties and early nineties, several active performance measurement tools were developed, e.g., ping, traceroute, ttcp, primarily for use by network managers when installing equipment, debugging the network, or monitoring basic performance metrics, such as round-trip times, loss rates (with periodic packet probing), number of hops, or bulk TCP throughput. These tools have demonstrated enormous practical operational value for network managers, but they do not measure more advanced performance metrics, such as capacity or available bandwidth across a path or of a certain link in the path.
- Second generation: Starting in the mid-nineties, several large-scale measurement activities used first-generation tools (and slightly modified derivatives) to evaluate and monitor the performance of various infrastructures: PingER (SLAC) [3], NIMI (LBNL, PSC, ACIRI), Surveyor (Advanced Networks), RIPE's Test Traffic, AMP (NLANR), Wolski's NWS, Skitter (CAIDA), and several commercial efforts, e.g., Keynote, MIDS, Internet Weather Services. For a comprehensive list of such measurement infrastructures, see [4] and [2]. A common characteristic of these projects is the large number of probing hosts distributed around the US or world. An important point in these projects is that N probes allow bi-directional monitoring of N2 network paths. Results from these projects have been of solid (yet limited) value in monitoring and visualizing approximate network performance. Their results are, however, virtually impossible to correlate, and they do not do well at capturing and analyzing performance data in time to take immediate operational actions based on the measurements. Further, none of the activities involved mechanisms for making measurement results available to transport protocols, applications, or middleware to improve end-to-end performance.
- Third generation: To make an innovative contribution to the field, the next generation of measurement technology must capture more advanced performance metrics, such as capacity (maximum possible throughput) and available bandwidth (maximum allowable throughput) of a network path. Such metrics are more useful to an application than simple round-trip time or loss rate estimates. Other advanced performance metrics related to available bandwidth include: delay variations (jitter), stationarity of cross traffic, and distribution of queue sizes along the network path. In addition, third generation tools must make gathered information available to applications, transport protocols, and network middleware for use in modulating end host behavior to optimize end-to-end performance. This latter task is tremendous in scope and difficulty, involving re-consideration of schemes used for flow and congestion control, load-adaptive routing and traffic engineering, and measurement-based class differentiation. All of these schemes can be radically improved with `educated guesses' of bandwidth characteristics of the underlying network.
The main context of this proposed research is efficient support of data-intensive scientific applications in high-performance networks. Our research targets both BMMs and their use in and BAPs. BMMs estimate bandwidth-related performance metrics important for users and applications, while BAPs close the loop between network operations and network measurements to optimize end-to-end performance. Section 2 provides more precise definitions of bandwidth metrics and classifies existing bandwidth measurement methodologies. Section 3 reviews relevant previous research results and tools. Section 4 details our research objectives in more detail, and the techniques we will investigate. Section 5 discusses how we plan to test the tools on networks of interest to DOE.
2 Definitions and Classifications
We first define bandwidth-related metrics for a network path. Two end-to-end bandwidth metrics commonly associated with a path are its capacity C and available bandwidth A. Capacity is the maximum IP-layer throughput that a path can provide to a flow when there is no competing traffic load (cross traffic). Available bandwidth, on the other hand, is the maximum IP-layer throughput that the path can provide to a flow, given the path's current cross traffic load. The link with the minimum transmission rate determines the capacity (C) of the path, while the link with the minimum unused capacity limits the available bandwidth (A). To avoid the term bottleneck link that has been widely used for both metrics, we refer to the capacity limiting link as the narrow link, and to the available bandwidth limiting link as the tight link. Specifically, if H is the number of hops in a path, Ci is the transmission rate or capacity of link i, and C0 is the transmission rate of the source,
| (1) |
| (2) |
We classify bandwidth measurement methodologies in several ways. First, measurement tools in general can either be active or passive. Active measurements inject probe packets into the network and observe their behaviour. In contrast, passive measurements observe actual traffic without perturbing the network. To our knowledge there has been no significant work on passive measurement techniques for bandwidth estimation; the closest is Nevil Brownlee's work on web session performance [5]. We believe that hybrid techniques that correlate data from both kinds of measurement modes have strong potential for evaluation of several performance metrics, including bandwidth-related ones.
Second, we consider the type of measured metrics: end-to-end and hop-by-hop. End-to-end methodologies measure the path capacity C and available bandwidth A [6,7,8]. In hop-by-hop methodologies, the objective is to measure the link capacity Ci of each link i in the path, and if possible, the utilization (or load) of that link ui [9,10,11]. Both types of methodologies have been used. End-to-end bandwidth metrics are more directly relevant to applications and transport protocols, since the capacity C determines the maximum possible throughput that a flow can achieve across the path, while available bandwidth quantifies the maximum throughput attainable by a flow, given a cross traffic load. Hop-by-hop bandwidth metrics, on the other hand, are perceived as useful for network operations, debugging, and traffic engineering, especially in those cases where traffic engineers have limited view or access to the entire path. Note that end-to-end bandwidth metrics can be computed from hop-by-hop bandwidth metrics if the latter are known. Unfortunately, estimating hop-by-hop bandwidth metrics is often significantly harder, so methodologies to measure only end-to-end metrics are useful and sometimes necessary. By empirically evaluating existing tools, we essentially test both approaches and can then target our development efforts to strategies offering the greatest chance of success.
A third classification of bandwidth monitoring methodologies is whether they are SNMP-gathered versus actively probed. In the former, operators use tools such as MRTG [12] to monitor utilization of individual links with information obtained from router management software via SNMP. These techniques use counters and configuration parameters maintained by routers, and normally are reasonably accurate. However, SNMP-based techniques require access to the router, which is usually limited to engineers for that network. Active probe methodologies, on the other hand, estimate bandwidth metrics by sending specific known patterns of packets across the measured path and measuring timing aspects of packets as they traverse the path. In general, these methodologies require only the cooperation of path end-points, not access to the router SNMP MIBs. Although end-to-end approaches are usually not as accurate as router-based methodologies, they are typically the only feasible approach for monitoring a path that crosses several networks due to organizational proprietorship. Additionally, it is easy for a network provider to provide false SNMP readings (by either accident or intent), so that a link claims to be of different capacity or load than it really is. Measurement-based methodologies do not suffer this drawback since they measure actual bandwidth characteristics of the path.
A fourth classification of bandwidth monitoring methodologies (which applies only to active measurement-based schemes) is whether they are network intrusive versus network friendly. In the former, the average rate of measurement traffic is significant compared to the available bandwidth in a path. As an example, a possible way to measure path capacity is to blast the path with a continuous stream of UDP packets that will gradually eliminate the congestion-responsive TCP traffic from the link, and measure (by consuming) the maximum possible throughput. Alternatively, one can estimate available bandwidth by filling the path with a TCP connection of sufficiently large receiver window, or using TCP-emulators such as TReno [13]. Examples of network-intrusive bandwidth measurement tools are NLANR's Iperf or the popular ttcp. Intrusive measurement methodologies incur significant overhead on the network and cannot be used operationally. Network friendly methodologies, on the other hand, estimate bandwidth metrics without generating significant measurement traffic relative to the available bandwidth. We limit ourselves to network friendly methodologies, since we are particularly interested in `always-on' bandwidth monitoring of network paths. The ideal situation would be analogous to the UNIX process sched, which monitors system load in the background, using a negligible fraction of CPU.
To summarize this classification, we focus on active probing and network-friendly bandwidth monitoring methodologies that estimate either end-to-end metrics (capacity and available bandwidth of a path), or hop-by-hop metrics (capacity and load of each link in the path). We will also pursue ways to correlate active measurements with passively collected data (timestamped packets) when the latter is available. We will use SNMP-based or network intrusive techniques only for correlation and validation.
3 Previous Results
Currently, two different bandwidth measurement methodologies exist: Variable Packet Size (VPS) probing [10], and Packet Train Dispersion (PTD) probing [8]. We have collaborated with developers of VPS tools, and have ourselves developed and implemented PTD tools.
VPS probing, originally proposed by Steve Bellovin [14] and by Van Jacobson [9], measures hop-by-hop metrics. These tools send IP (UDP) packets of various sizes into the network, record the response times of routers receiving those packets, and use this data to construct estimates of delay, bandwidth, and packet loss. Allen Downey further improved the basic VPS scheme [10], and both Allen Downey and Bruce Mah independently implemented it in clink [15], and pchar [16].
In a related effort, Kevin Lai and Mary Baker[29] have developed nettimer which performs expensive measurement calculations locally while using a distributed packet capture architecture as implemented by the libdpcap library. Another similar project is the Network Characterization Service (NCS) [30] which has been used to compare pchar and pipechar measurement results.VPS tools use variations in response time (as a function of packet size) to estimate the characteristics of links along a network path. An agent sends packets of varying sizes along a path, and uses minimum response times for each packet size to filter out effects of queueing at intermediate hops. By modulating the distance that packets are allowed to travel (as traceroute does), VPS techniques can measure response time distributions along partial paths from a source toward a destination. Differencing between partial path results yields estimates for individual hops.
clink and pchar are reimplementations and extensions of the original pathchar. clink implements adaptive probing techniques to vary the number of probes used to measure a given hop. A few packets are needed for links that are easy to characterize, i.e., have low noise in the measurements. Links for which it is harder to accurately capture signal from the noise in the measurements require sending a larger number of packets across them.
pchar focuses on portability across platforms and protocols, including IPv6, and multiple linear regression techniques. pchar implements some robust and non-parametric techniques to allow comparisons of accuracy of these algorithms in estimating network performance characteristics.
Packet Train Dispersion (PTD) probing, on the other hand, targets end-to-end bandwidth metrics. The PTD methodology has roots in the packet-pair model, originally described in [17], studied in the context of congestion control in [18], and applied as a capacity measurement methodology in [19]. Early works on PTD were followed by more sophisticated variations, such as the bprobe capacity estimation tool [7] and the statistical filtering technique [20]. Paxson observed that the distribution of bandwidth measurements is multimodal, and he elaborated on the identification and final selection of a capacity estimate from these modes [21].
PTD probing also has been applied to estimation of available bandwidth. Specifically, the cprobe methodology measures dispersion of eight-packet trains [7], while other researchers proposed that the ssthresh variable in TCP's slow-start phase should be determined from dispersion of the first three or four ACKs [22,23]. The underlying assumption in these proposals [7,22,23] is that the dispersion of long packet trains is inversely proportional to the available bandwidth. However, our past results showed that this assumption is invalid [8].
The same study ([8]) developed a capacity estimation methodology, focusing on the effects of cross traffic on the measurement process. We showed that a straightforward application of the packet pair technique cannot in general produce accurate results when cross traffic effects are ignored. The reason is that the distribution of bandwidth measurements is multimodal, and local modes, related to the cross traffic, are often stronger than the capacity mode. [8] also investigated the dispersion of long packet trains. Increasing the length of the packet train reduces the measurement variance, but the estimates converge to a value, referred to as Asymptotic Dispersion Rate (ADR), that is lower than the capacity.
As an application of the PTD methodology, Constantinos Dovrolis developed a capacity estimation scheme that has been implemented in a tool called pathrate. This methodology uses many packet pairs to discern the multimodal bandwidth distribution. Then, pathrate identifies the local modes, and selects the mode that corresponds to the path capacity. This capacity mode selection is based on the dispersion of gradually longer packet trains. The methodology is accurate when the capacity is between 10-40 Mbps and the specified estimate resolution is 1 Mbps. Higher capacity paths require a larger estimate resolution. pathrate is available at http://www.cis.udel.edu/~dovrolis/bwmeter.html/.
4 Research Objectives and Methods
As previously mentioned, our higher-level goal is to investigate Bandwidth Measurement Methodologies (BMMs) and Bandwidth-Aware Protocols (BAPs). In this section we describe these objectives in more detail.
4.1 Research on Bandwidth Measurement Methodologies
We will extend our previous work on VPS and PTD methodologies as follows:
- Improve accuracy: Existing BMMs (both VPS and PTD) often fail to provide accurate estimates. Depending on the specific measurement methodology or tool, the errors are more significant in heavily loaded paths, in higher bandwidth paths, or in paths with larger number of hops. Sometimes, the errors are exacerbated by special forwarding schemes in layer-2 technologies, such as multipath forwarding, parallel channel links, or QoS packet scheduling mechanisms. The often slow-path process that generates ICMP replies in routers can also affect the accuracy of BMMs that use ICMP replies (mainly VPS). Our first task will be to provide additional robustness in our existing methodologies and tools. Experimenting with the tools in operational networks, such as ESnet, will allow us to detect and analyze such errors, enhance the code with better statistical filtering techniques, and fine tune the various parameters that are inevitable in any BMM.
- Make higher bandwidth measurements: Most existing bandwidth measurement tools have been tested in paths with a capacity of at most 100Mbps. The challenge of measuring bandwidth characteristics of OC-12 or OC-48 links is enormous, as the transmission time of an MTU packet is reduced to a few microseconds. Slight timing errors measuring such links can cause estimation failures. We anticipate that for the measurement of high-bandwidth links, in the range of OC-3 to OC-48, we will need measurement hosts with highly accurate clocks, as well as timestamps at the kernel or at the network interface.
- Use distributed measurement infrastructure: The use of distributed measurement infrastructures is crucial in evaluating the accuracy of link characterizations. In addition to improving the accuracy of the bandwidth estimation process, these systems permit us to measure a given link from various directions. Correlating and coordinating multiple measurements of the same link offers additional insight into its link characteristics. Section 5 discusses how we plan to test the tools on networks of interest to the ESnet community.
- Evaluate improved VPS methods: In addition to the original work by Van Jacobson and the extensions by Downey and Mah, other research groups have proposed improved statistical techniques for estimating link characteristics. Unfortunately, without a large and diverse collection of links with known characteristics, it has been difficult to compare these methods or evaluate their accuracy. CAIDA's distributed measurement infrastructure (based on deployed skitter monitors, will make this evaluation possible.
In addition to extending our previous BMMs and tools, we will investigate original BMMs with the following objectives:
- Correlate delay variations with available bandwidth measurements: Even though the available bandwidth A was investigated in [8], we still do not have a BMM that accurately measures A in a network friendly manner. Preliminary results, however, have convinced us that there is a correlation between delay variations in a path and available bandwidth. Paxson [24] also has observed such correlation. We currently experiment with a scheme that estimates A using gradually longer packet trains, and simultaneously monitors the additional queueing load that these trains impose on the path.
- Correlate passive measurements with available bandwidth measurements: Although we will only be able to get passive data from few locations, we will use such data, where available at sufficient timestamp granularity, to augment our active measurement results, and pursue ways to integrate such tecniques where viable.
- Characterize the effect of non-stationarity of cross-traffic: A major challenge in measurement of available bandwidth is that cross traffic can be strongly non-stationary (or, according to some researchers, long-range dependent), which means that variance in available bandwidth measurements can be excessive, even across relatively large timescales. Consequently, one of our objectives is to examine whether these concerns are valid in networks with highly aggregated traffic, and to identify meaningful timescales for measurement of available bandwidth. Instead of filtering out a large fraction of bandwidth measurements to produce a final estimate for the path capacity or available bandwidth, we can use the entire range of bandwidth measurements to examine statistical properties of traffic in high performance networks. These properties will quantify the stationarity and predictability of the cross traffic intensity, an issue of major importance in transport protocol design.
- Characterize the effect of routing dynamics and asymmetry on real paths: Existing VPS techniques do not effectively handle certain network conditions, such as alternating paths and asymmetric paths. Section 5 provides an example visualization of the number of possible commodity forward IP paths between two randomly selected hosts on CAIDA's skitter infrastructure. By leveraging CAIDA's distributed measurement architecture, as well as platforms on ESnet, we will have access to real links with significant cross-traffic and routing changes but whose actual capacities we are likely to be able to find out. Heterogeneous distributed testing platforms will not only improve the accuracy of these methods; it will also make it possible for them to deal with these anomalies. Such infrastructure will make it possible to compare the proposed techniques to each other, and provide a more reliable standard of accuracy.
4.2 Research on Bandwidth-Aware Protocols
Knowledge of end-to-end or hop-by-hop bandwidth characteristics is of little value unless it leads to improved application performance and better network utilization. As previously mentioned, a central component in this proposed work is the development of a feedback loop that provides the bandwidth measurements to either the applications or transport protocols at the end points, or to middleware in the network. Benefits of this feedback loop are considerable:
- Bandwidth-aware transport protocols: A transport protocol such as TCP can use an educated guess of the available bandwidth of a path to set its ssthresh parameter [25]. If some type of pacing is used, the transport protocol can initialize its sending rate to a certain fraction of the available bandwidth. Similarly, a transport protocol need not wait for a packet loss before reducing its rate. Losses in TCP cause significant throughput losses, even with its fast recovery/retransmission schemes. Another way to react to congestion is to dynamically monitor the available bandwidth in the path. When the latter shows a sudden decrease, the transport protocol could reduce its sending rate or window, before a loss occurs. We will experiment with such techniques, starting with existing TCP code, and enhancing it with algorithms that make use of capacity or available bandwidth estimates.
- Bandwidth-aware traffic engineering and path selection: Significant benefits in network utilization (and in end-to-end performance) result if routing is not only based on a shortest-path algorithm, but also considers the capacity and load of network paths. The challenge is to design middleware algorithms that dynamically monitor bandwidth characteristics of each network link, thereby providing the routing protocol, or traffic engineering protocol, with information about an optimal path. In this context, a user (or more likely, middleware at the network edge) will ask the routing protocol for a certain path that provides capacity of at least X, or available bandwidth of at least Y Mbps.
- Bandwidth-aware service differentiation: Even though it is unlikely that QoS mechanisms of fine, per-flow granularity will be deployed in the near future, some class-based differentiation mechanisms can be useful for offering controllable discrimination among diverse traffic types and users. These mechanisms include class-based packet scheduling and input traffic limiting (or admission control). Such mechanisms have to be adaptive to the intensity of the traffic load in each class. Consequently, bandwidth estimates that are generated separately for each class can be used to reconfigure service differentiation parameters and ingress traffic limits in order to provide a certain QoS grade to each class. Although there is only limited deployment of QoS mechanisms in operational networks, ESnet routers are equipped with CBQ schedulers (see http://www.lbl.gov/CS/qos.html/). Thus, we are uniquely placed to experiment, at least initially, with dynamic adjustments of the CBQ weights based on the bandwidth measurements in the corresponding link.
5 Infrastructures for testing
There are several different places we intend to test our analysis methodologies and tools.
First, both Les Cottrell (SLAC) and Ian Foster (ANL) have expressed interest and support regarding use of our tools and methodologies on their DOE projects [26,2] (see attached copies of email.) SLAC/DOE/Esnet, HEPnet and HENP use pingER tools to actively monitor end-to-end Internet performance for accelerator labs and collaborating universities. Les Cottrell is planning to build an expanded active measurement infrastructure for ESnet, for which bandwidth estimation tools would be an optimal addition.
Ian Foster has expressed the need for bandwidth estimation for his work on data replica selection strategies for data-intensive applications, configuration of high-performance transfers, and configuration of distance visualization pipelines. Currently they use a mixture of Rich Wolski's Network Weather Service [27] as a persistent measurement infrastructure, and pchar for more detailed analysis. As expected, translating results of the measurements into reasonable decisions at higher levels is a particular challenge for this project, and one we target in our proposal.
The Network Weather Service itself [27], which periodically monitors and dynamically forecasts performance available from various NPACI network and computational resources over a given time interval, would also benefit from the proposed work.
Infrastructures such as NIMI and skitter, who use the commodity Internet infrastructure, are subject to sometimes an impressive degree of path dynamics. For example, for 83 traces taken over a 72 hour period to a single destination, skitter recorded 81 unique paths. Such highly dynamic paths appear to occur due to load balancing at multiple path points. CAIDA keeps long-term topology and performance data for skitter paths from hosts to each other at frequent intervals, allowing us to select host pairs with a range of path dynamics, and correlate our measurements with those operationally gathered by skitter. We are also enhancing CAIDA's otter visualization tool to illustrate multiple paths and color by bandwidth, frequency used, and difference between measured and actual bandwidth (see figure 1).
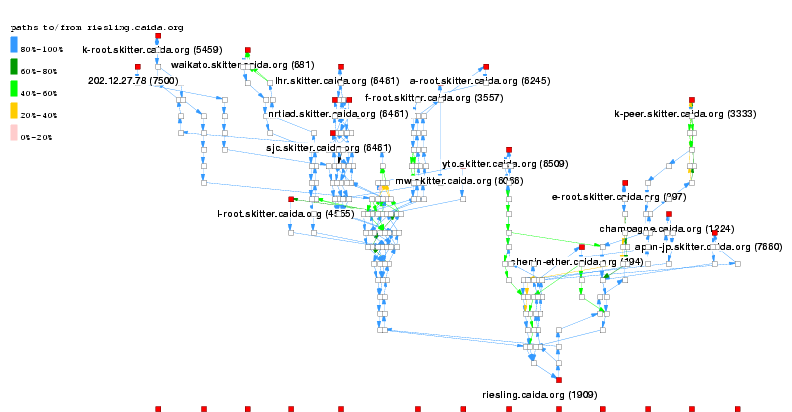
| from 192.172.226.24 | numDests with numUniqPaths | |||||||
| numDays | avgNumTracesPerDst | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1 | 27.75 | 6 | 6 | 1 | 3 | 0 | 0 | 0 |
| 2 | 55.75 | 5 | 7 | 1 | 2 | 0 | 1 | 0 |
| 3 | 83.50 | 5 | 7 | 0 | 3 | 0 | 0 | 1 |
Figure 2 (also using otter) illustrates the subset of these links probed from the same (riesling's) subnet during our pchar experiments, and the resulting bandwidth estimates. We have gathered actual bandwidth information for many of these links (and are in the process of gathering the rest and establishing a database to hold the information) so we can assess the error.
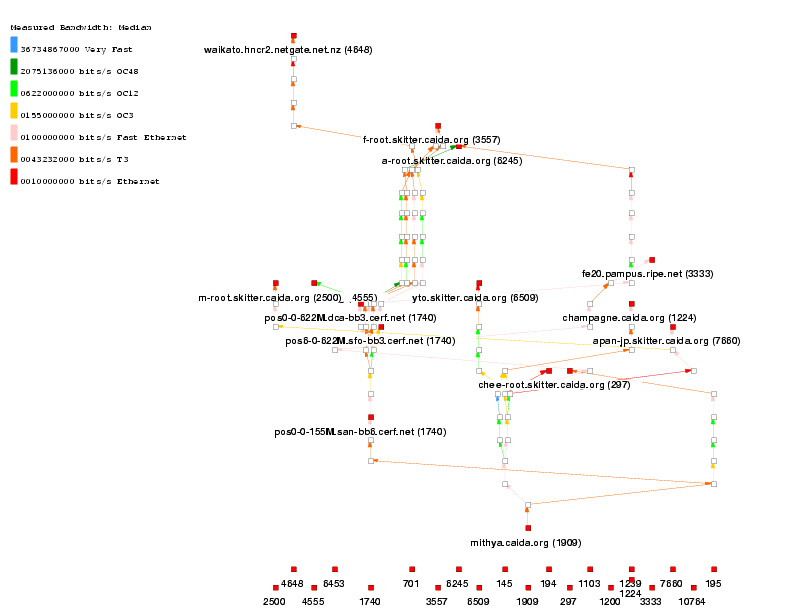
Once we are comfortable with the techniques we can reimplement CAIDA's Mapnet [28] to dynamically measure backbone bandwidths rather than reading the data from a static file. Upgrading Mapnet to maintain this database dynamically is an ambitious task but CAIDA has received strong indications of community interest for Mapnet, which is essentially impossible to keep accurate manually.
6 Task list
Our research will focus on four directions:- Measurement tool suite incorporating new bandwidth estimation algorithms
- Database back end and user interface for navigating the data
- Distributed measurement infrastructure for testing techniques
- Mechanisms to incorporate results into flexible application and middleware software
The tool suite will include pathrate, by Constantinos Dovrolis. The suite will generate a variety of probes, collect measurements in database files, and then transport these files to a central location for analysis. We will use this suite to study ways to reduce the effects of experimental error. Additionally, we will use a distributed infrastructure of measurement stations (including DOE collaborating sites) that can continuously measure in real-time the load of all paths between these stations. In preparation for establishing a prototype bandwidth estimation testbed mesh, CAIDA has already begun to gather the necessary link bandwidth data on its skitter infrastructure from ISPs.
K. C. Claffy, CAIDA-UCSD: The primary tasks for K. C. Claffy will be:
- Overall coordination and integration of project pieces
- Deployment and testing of developed modules on CAIDA and DOE measurement infrastructure
- Establish and maintain database of actual bandwidth characteristics of measured links
- Visualization of experiments and results
- Correlation of active with passive techniques (header capture) for estimating available bandwidth
- Use resulting tools to upgrade Mapnet to dynamically measure backbone bandwidths
- Ensure technology transfer to DOE community
Constantinos Dovrolis, University of Delaware The primary tasks for C. Dovrolis will be:
- PTD methods for end-to-end capacity measurements
- PTD methods for end-to-end available bandwidth measurements
- Bandwidth-aware transport protocols
- Bandwidth-aware traffic engineering and path selection
- Bandwidth-aware service differentiation
7 Conclusion
As the Internet infrastructure grows in scope, performance, and range of incorporated technologies, challenges arise for applications to effectively take advantage of its new capacities. Real-time applications can only adapt to dynamically changing network characteristics if application network requirements can be mapped to metrics such as bandwidth and associated link delay, jitter, queue length, and loss. Yet accurate measurement of bandwidth capacity (the maximum throughput available to all applications), and available bandwidth (actual available throughput given competing traffic load) defies easy calculation. Better bandwidth measurement algorithms are needed by a large class of network applications, traffic engineers controlling path selection and service class differentiation, and users wanting to verify they are receiving the access bandwidth they expect. Better bandwidth monitoring tools are also needed to detect congested or underutilized links as well as for planning capacity upgrades. Combining better end-to-end performance measurements with real-time knowledge of link characteristics will allow a quantum leap in the field of traffic engineering, and also support bandwidth brokering among applications and distributed network resources.
Significant contributions in bandwidth measurement technologies have already been made by project investigators, and we intend to make improvements in existing tools and to test and integrate such tools into DOE and other network infrastructures. The proposed effort will overcome existing limitations of algorithms (such as those used in pathchar), whose estimates degrade as the distance from the probing host increases. Our experience with both VPS and PTD probing techniques puts us in a good position to take on this research challenge. As we improve algorithms for both, we will incorporate our knowledge into an integrated tool suite that offers insights into both kinds of infrastructure characteristics. We will also investigate mechanisms for incorporating bandwidth measurement methodologies into applications or operating systems, so that the applications quickly reach the highest throughput a path can provide. Finally, we will examine ways in which routing protocols, traffic engineering, and network resource management systems can use accurate bandwidth estimation techniques in order to improve overall network efficiency.
References
- [1]
- T. Dunigan, ``Optimizing bulk transfers over high latency/bandwidth nets,'' tech. rep., Oak Ridge National Lab, Feb. 2001. http://www.csm.ornl.gov/ ~ dunigan/netperf/bulk.html.
- [2]
- L. Cottrell, M. Zekauskas, H. Uijterwaal, and T. McGregor, ``Comparison of some Internet Active End-to-end Performance Measurement projects ,'' tech. rep., SLAC - IEPM, July 1999. http://www.slac.stanford.edu/comp/net/wan-mon/iepm-cf.html.
- [3]
- W. Matthews and L.Cottrell, ``The PINGer Project: Active Internet performance monitoring,'' IEEE Communications Magazine, pp. 130-137, May 2000.
- [4]
- M. Murray, ``Internet Measurement Infrastructure.'' https://www.caida.org/analysis/perfor-mance/measinfra/, Jan. 2001.
- [5]
- N. Brownlee, ``NeTraMet Web Session Performance Analysis.'' https://www.caida.org/research/traffic-analysis/netramet/web/, July 2000.
- [6]
- V. Paxson, ``End-to-End Internet Packet Dynamics,'' IEEE/ACM Transaction on Networking, vol. 7, pp. 277-292, June 1999.
- [7]
- R. Carter and M.E.Crovella, ``Measuring Bottleneck Link Speed in Packet-Switched Networks,'' Performance Evaluation, vol. 27,28, pp. 297-318, 1996.
- [8]
- C. Dovrolis, P. Ramanathan, and D. Moore, ``What do Packet Dispersion Techniques Measure?,'' in Proceedings of IEEE INFOCOM, Apr. 2001.
- [9]
- V. Jacobson, ``pathchar: A Tool to Infer Characteristics of Internet Paths.'' ftp://ftp.ee.lbl.gov/pathchar/, Apr. 1997.
- [10]
- A. Downey, ``Using Pathchar to Estimate Internet Link Characteristics,'' in ACM SIGCOMM, Sept. 1999.
- [11]
- K. Lai and M.Baker, ``Measuring Link Bandwidths Using a Deterministic Model of Packet Delay,'' in Proceedings ACM SIGCOMM, Sept. 2000.
- [12]
- T. Oetiker, ``MRTG: Multi Router Traffic Grapher.'' http://ee-staff.ethz.ch/ ~ oetiker/webtools/mrtg/mrtg.html.
- [13]
- M. Mathis, TReno Bulk Transfer Capacity, Feb. 1999. draft-ietf-ippm-treno-btc-03.txt.
- [14]
- S. Bellovin, ``A Best-Case Network Performance Model,'' tech. rep., ATT Research, Feb. 1992.
- [15]
- A. Downey, ``clink: a Tool for Estimating Internet Link Characteristics.'' http://rocky.wellesley.edu/downey/clink/, June 1999.
- [16]
- B. A. Mah, ``pchar: a Tool for Measuring Internet Path Characteristics.'' http://www.employees.org/ ~ bmah/Software/pchar/, June 2000.
- [17]
- V. Jacobson, ``Congestion Avoidance and Control,'' in Proceedings ACM SIGCOMM, pp. 314-329, Sept. 1988.
- [18]
- S. Keshav, ``A Control-Theoretic Approach to Flow Control,'' in Proceedings ACM SIGCOMM, Sept. 1991.
- [19]
- J. C. Bolot, ``Characterizing End-to-End Packet Delay and Loss in the Internet,'' in Proceedings ACM SIGCOMM, pp. 289-298, 1993.
- [20]
- K. Lai and M.Baker, ``Measuring Bandwidth,'' in Proceedings IEEE INFOCOM, Apr. 1999.
- [21]
- V. Paxson, Measurements and Analysis of End-to-End Internet Dynamics. PhD thesis, University of California, Berkeley, Apr. 1997.
- [22]
- J. Hoe, ``Improving the Start-up Behavior of a Congestion Control Scheme for TCP,'' in Proceedings ACM SIGCOMM, Sept. 1996.
- [23]
- L. S. Brakmo and L.L.Peterson, ``TCP Vegas: End to End Congestion Avoidance on a Global Internet,'' IEEE Journal on Selected Areas of Communications, vol. 13, Oct. 1995.
- [24]
- V. Paxson, ``End-to-end Internet Packet dynamics,'' in Proceedings SIGCOMM Symposium, Sept. 1997.
- [25]
- M. Allman and V. Paxson, ``On Estimating End-to-End Network Path Properties,'' in ACM SIGCOMM, Sept. 1999.
- [26]
- W. Matthews, ``The PingER Project Summary and Detail Reports,'' tech. rep., SLAC - IEPM, Nov. 2001. http://www-iepm.slac.stanford.edu/pinger/.
- [27]
- R. Wolksi, NWS: Network Weather Service, Feb. 2001. http://nws.npaci.edu/NWS/.
- [28]
- CAIDA, ``Mapnet: Macroscopic Internet Visualization and Measurement.'' https://www.caida.org/tools/visualization/mapnet/, July 1997.
- [29]
- K. Lai and M. Baker, ``Nettimer: A Tool for Measuring Bottleneck Link Bandwidth.'' April 2001, http://citeseer.nj.nec.com/lai01nettimer.html
- [30]
- G. Jin, G. Yang, B. Crowley and D. Agarwal, ``Network Characterization Service(NCS)'', Lawrence Berkeley National Lab report #47892. 2001.
File translated from TEX by TTH, version 2.92.
On 24 May 2001, 18:47.